第三部分:集群测试&配置历史服务器
集群测试
HDFS 分布式存储初体验
从linux本地文件系统上传下载文件验证HDFS集群工作正常
# 在HDFS文件系统根目录下面创建文件夹
hdfs dfs -mkdir -p /test/input
#本地home目录创建一个文件
vim /root/test.txt
hello hdfs
#上传linxu文件到Hdfs
hdfs dfs -put /root/test.txt /test/input
# 删除本地文件
rm -rf /root/test.txt
#从Hdfs下载文件到linux本地
hdfs dfs -get /test/input/test.txtMapReduce 分布式计算初体验
在HDFS文件系统根目录下面创建一个wcinput文件夹
[root@linux121 hadoop-2.9.2]$ hdfs dfs -mkdir /wcinput在/root/目录下创建一个wc.txt文件(本地文件系统),并进行编辑
vi /root/wc.txt
hadoop mapreduce yarn
hdfs hadoop mapreduce
mapreduce yarn lagou
lagou lagou上传wc.txt到Hdfs目录/wcinput下
hdfs dfs -put wc.txt /wcinput执行程序
\wcoutput目录无需手动创建,程序执行过程中会创建
[root@linux121 hadoop-2.9.2]$ /opt/lagou/servers/hadoop-2.9.2/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.9.2.jar wordcount /wcinput /wcoutput查看结果
[root@linux121 hadoop-2.9.2]# hdfs dfs -cat /wcoutput/part-r-00000
hadoop 2
hdfs 1
lagou 3
mapreduce 3
yarn 2
本机查看hdfs目录
访问 http://192.168.80.121:50070/dfshealth.html#tab-overview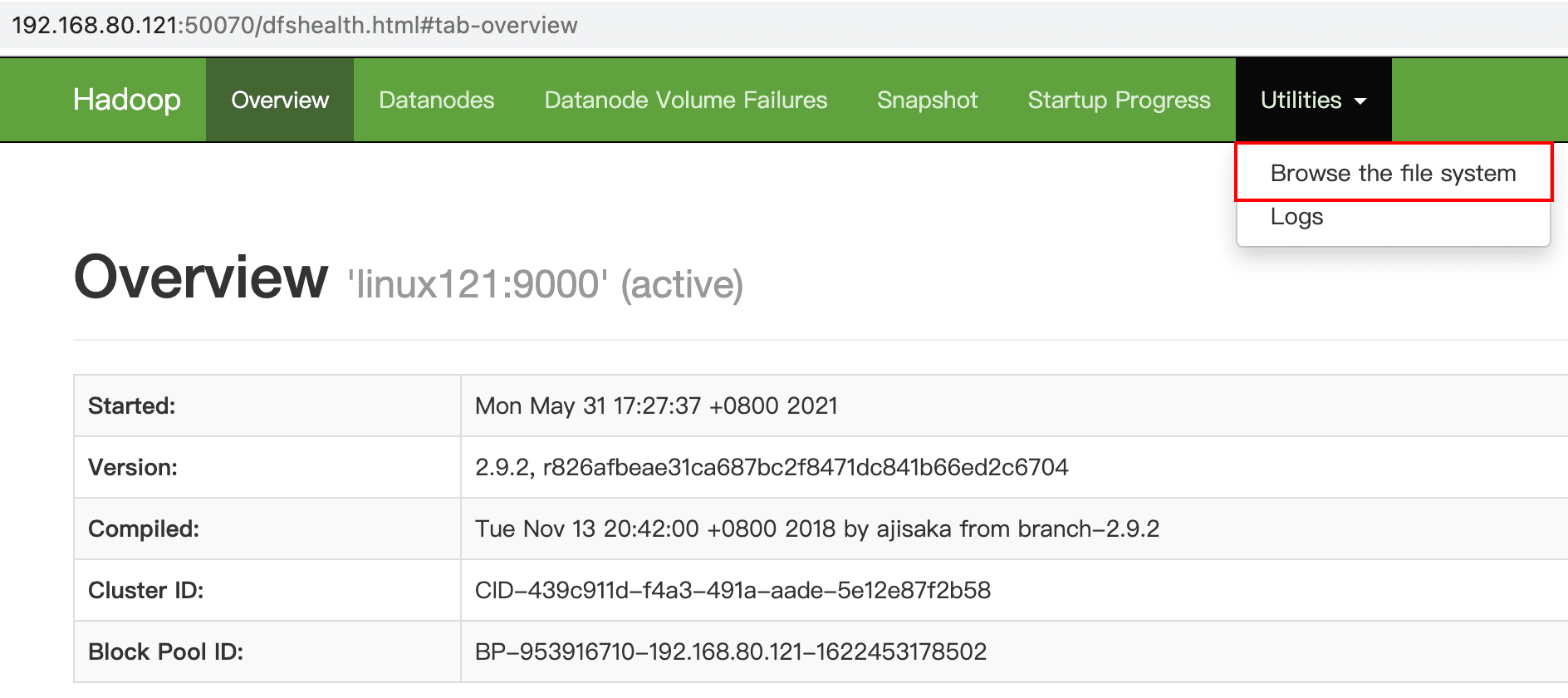
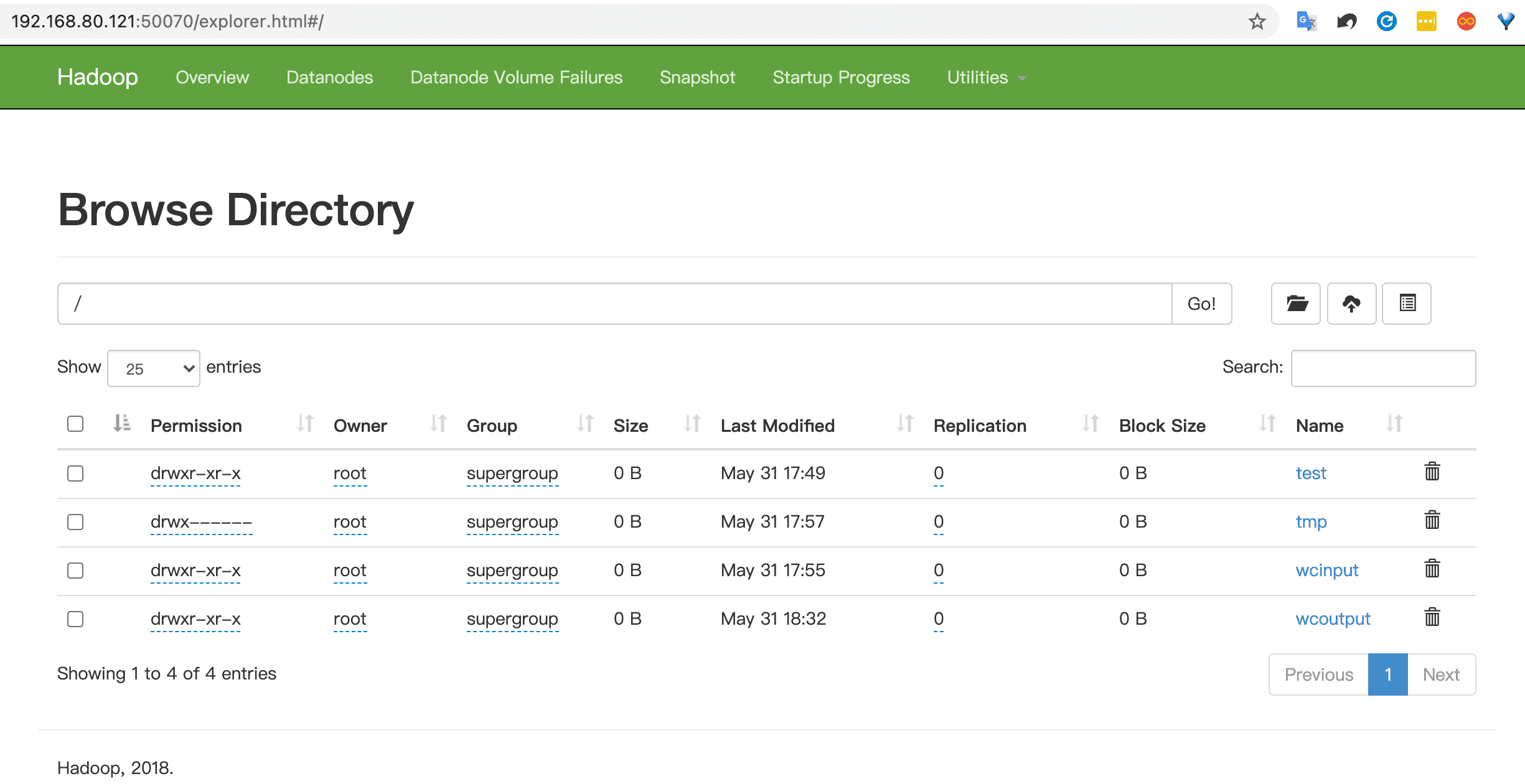
配置历史服务器
在Yarn中运行的任务产生的日志数据不能查看,为了查看程序的历史运行情况,需要配置一下历史日志服务器
- 配置mapred-site.xml
[root@linux121 hadoop]# vi /opt/lagou/servers/hadoop-2.9.2/etc/hadoop/mapred-site.xml # 添加以下配置 <!-- 历史服务器端地址 --> <property> <name>mapreduce.jobhistory.address</name> <value>linux121:10020</value> </property> <!-- 历史服务器web端地址 --> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>linux121:19888</value> </property> - 分发mapred-site.xml到其它节点
rsync-script mapred-site.xml- 启动历史服务器
[root@linux121 hadoop-2.9.2]$ sbin/mr-jobhistory-daemon.sh start historyserver
starting historyserver, logging to /opt/lagou/servers/hadoop-2.9.2/logs/mapred-root-historyserver-linux121.out- 查看历史服务器是否启动
[root@linux121 hadoop-2.9.2]$ jps
...
82008 JobHistoryServer
...- 查看JobHistory
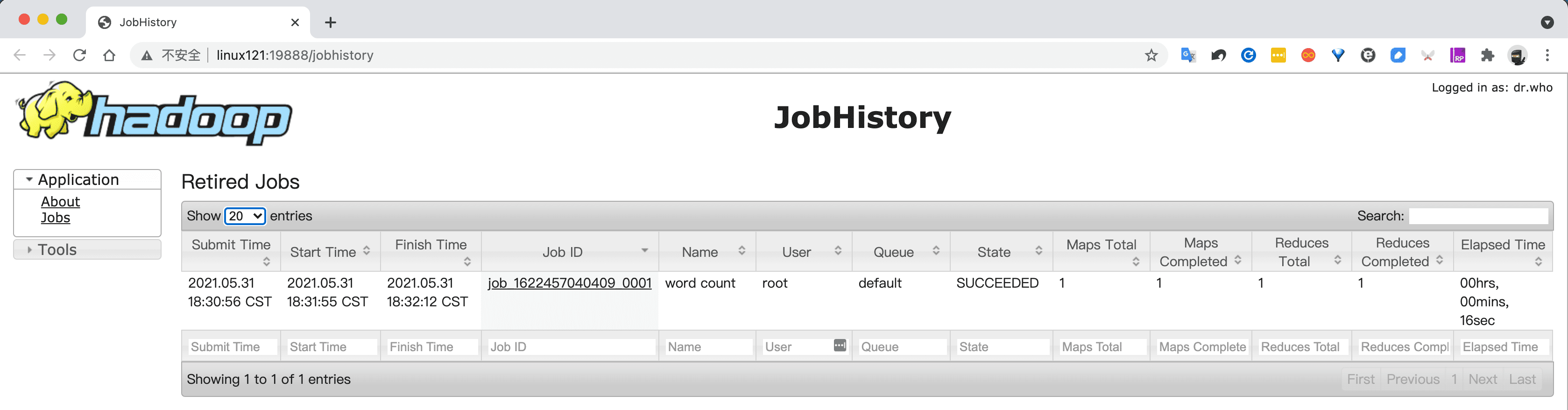
配置日志的聚集
- 日志聚集:应用(Job)运行完成以后,将应用运行日志信息从各个task汇总上传到HDFS系统上。
- 日志聚集功能好处:可以方便的查看到程序运行详情,方便开发调试。
注意:开启日志聚集功能,需要重新启动NodeManager 、ResourceManager和 HistoryManager。
- 配置yarn-site.xml
[root@linux121 hadoop]$ vi yarn-site.xml
# 新增以下配置
<!-- 日志聚集功能使能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 日志保留时间设置7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
<property>
<name>yarn.log.server.url</name>
<value>http://linux121:19888/jobhistory/logs</value>
</property>- 分发yarn-site.xml到集群其它节点
rsync-script yarn-site.xml- 重启历史服务器节点的NodeManager 、ResourceManager和HistoryManager
# 关闭
[root@linux121 hadoop-2.9.2]$ sbin/yarn-daemon.sh stop resourcemanager
[root@linux121 hadoop-2.9.2]$ sbin/yarn-daemon.sh stop nodemanager
[root@linux121 hadoop-2.9.2]$ sbin/mr-jobhistory-daemon.sh stop historyserver
# 开启
[root@linux121 hadoop-2.9.2]$ sbin/yarn-daemon.sh start resourcemanager
[root@linux121 hadoop-2.9.2]$ sbin/yarn-daemon.sh start nodemanager
[root@linux121 hadoop-2.9.2]$ sbin/mr-jobhistory-daemon.sh start historyserver- 删除HDFS上已经存在的输出文件
[root@linux121 hadoop-2.9.2]$ bin/hdfs dfs -rm -R /wcoutput- 执行WordCount程序
[root@linux121 hadoop-2.9.2]$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.9.2.jar wordcount /wcinput /wcoutput- 查看日志,如图所示
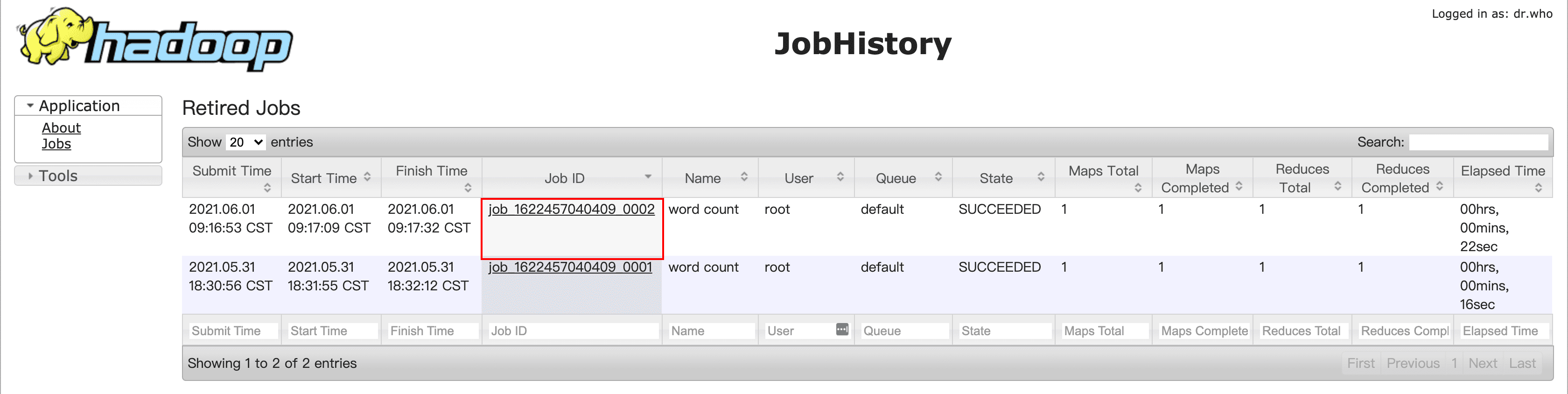
点击Job ID查看任务详情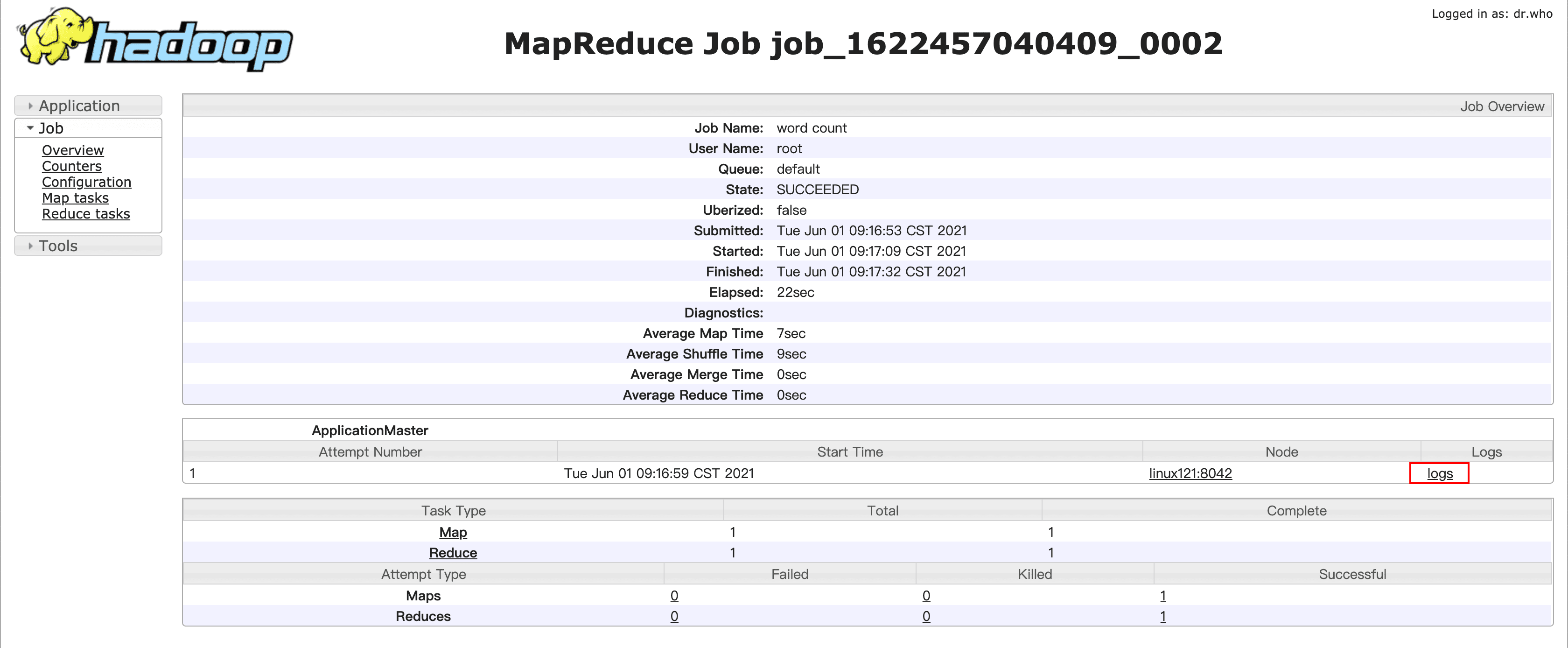
点击logs查看日志详情



