第二部分:集群规划&安装Hadoop
集群规划

安装Hadoop
登录linux121节点;进入/opt/lagou/software,解压安装文件到/opt/lagou/servers
tar -zxvf hadoop-2.9.2.tar.gz -C /opt/lagou/servers查看是否解压成功
ll /opt/lagou/servers/hadoop-2.9.2添加Hadoop到环境变量 vim /etc/profile
##HADOOP_HOME
export HADOOP_HOME=/opt/lagou/servers/hadoop-2.9.2
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin使环境变量生效
source /etc/profile验证hadoop
hadoop version
hadoop目录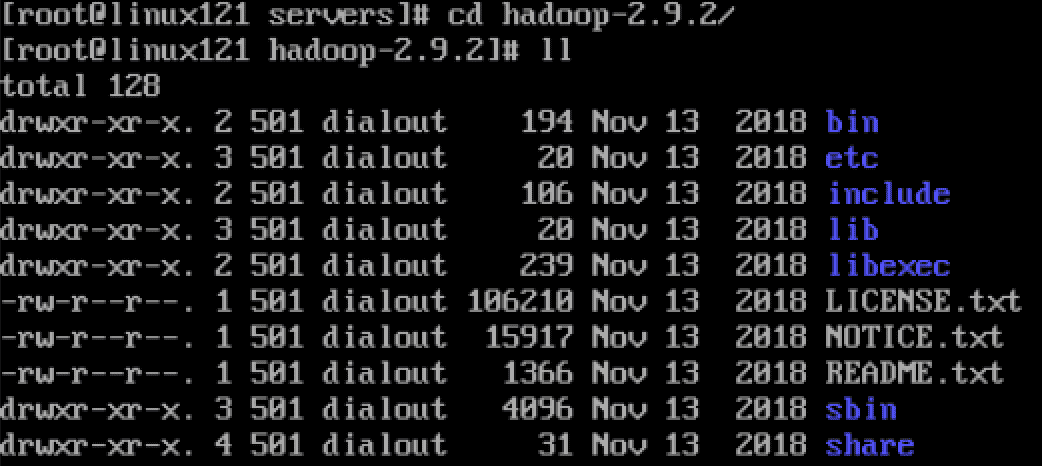
1. bin目录:对Hadoop进行操作的相关命令,如hadoop,hdfs等
2. etc目录:Hadoop的配置文件目录,入hdfs-site.xml,core-site.xml等
3. lib目录:Hadoop本地库(解压缩的依赖)
4. sbin目录:存放的是Hadoop集群启动停止相关脚本,命令
5. share目录:Hadoop的一些jar,官方案例jar,文档等集群配置
Hadoop集群配置 = HDFS集群配置 + MapReduce集群配置 + Yarn集群配置
HDFS集群配置
- 将JDK路径明确配置给HDFS(修改
hadoop-env.sh) - 指定NameNode节点以及数据存储目录(修改
core-site.xml) - 指定SecondaryNameNode节点(修改hdfs-site.xml)
- 指定DataNode从节点(修改etc/hadoop/slaves文件,每个节点配置信息占一行)
MapReduce集群配置
- 将JDK路径明确配置给MapReduce(修改
mapred-env.sh) - 指定MapReduce计算框架运行Yarn资源调度框架(修改
mapred-site.xml)
Yarn集群配置
- 将JDK路径明确配置给Yarn(修改
yarn-env.sh) - 指定ResourceManager老大节点所在计算机节点(修改
yarn-site.xml) - 指定NodeManager节点(会通过slaves文件内容确定)
HDFS集群配置
cd /opt/lagou/servers/hadoop-2.9.2/etc/hadoop- 配置:hadoop-env.sh,将JDK路径明确配置给HDFS
vim hadoop-env.sh
export JAVA_HOME=/opt/lagou/servers/jdk1.8.0_231- 指定NameNode节点以及数据存储目录(修改core-site.xml)
覆盖原文件信息
vim core-site.xml
<configuration>
<!-- 指定HDFS中NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://linux121:9000</value>
</property>
<!-- 指定Hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/lagou/servers/hadoop-2.9.2/data/tmp</value>
</property>
</configuration>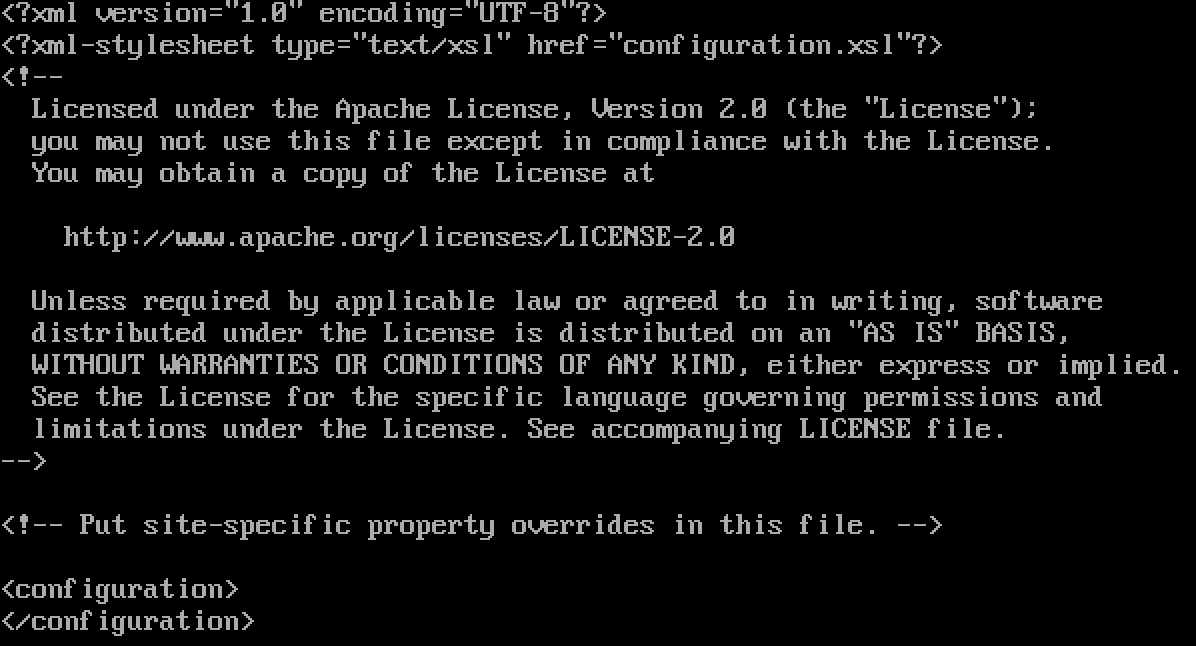
指定secondarynamenode节点(修改hdfs-site.xml)
vim hdfs-site.xml <configuration> <!-- 指定Hadoop辅助名称节点主机配置 --> <property> <name>dfs.namenode.secondary.http-address</name> <value>linux123:50090</value> </property> <!--副本数量 --> <property> <name>dfs.replication</name> <value>3</value> </property> </configuration>指定datanode从节点(修改slaves文件,每个节点配置信息占一行)
vim slaves linux121 linux122 linux123
注意:该文件中添加的内容结尾不允许有空格,文件中不允许有空行。
MapReduce集群配置
- 指定MapReduce使用的jdk路径(修改mapred-env.sh)
vim mapred-env.sh
export JAVA_HOME=/opt/lagou/servers/jdk1.8.0_231- 指定MapReduce计算框架运行Yarn资源调度框架(修改mapred-site.xml)
mv mapred-site.xml.template mapred-site.xml
vim mapred-site.xml
<configuration>
<!-- 指定MR运行在Yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>Yarn集群配置
- 指定JDK路径
vim yarn-env.sh
export JAVA_HOME=/opt/lagou/servers/jdk1.8.0_231- 指定ResourceMnager的master节点信息(修改yarn-site.xml)
vim yarn-site.xml
<configuration>
<!-- 指定YARN的ResourceManager的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>linux123</value>
</property>
<!-- Reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>- 指定NodeManager节点(slaves文件已修改)
注意: Hadoop安装目录所属用户和所属用户组信息,默认是501 dialout,而我们操作Hadoop集群的用户使 用的是虚拟机的root用户, 所以为了避免出现信息混乱,修改Hadoop安装目录所属用户和用户组!!
chown -R root:root /opt/lagou/servers/hadoop-2.9.2分发配置
编写集群分发脚本rsync-script,用于同步linux121的配置信息到linux122、linux123中
rsync主要用于备份和镜像。具有速度快、避免复制相同内容和支持符号链接的优点。
rsync和scp区别:用rsync做文件的复制要比scp的速度快,rsync只对差异文件做更新。scp是把所有文 件都复制过去。
- 基本语法
rsync -rvl $pdir/$fname $user@$host:$pdir/$fname
命令 选项参数 要拷贝的文件路径/名称 目的用户@主机:目的路径/名称| 选项 | 功能 |
|---|---|
| -r | 递归 |
| -v | 显示复制过程 |
| -l | 拷贝符号连接 |
rsync案例
- 三台虚拟机安装rsync (执行安装需要保证机器联网)
[root@linux121 ~]# yum install -y rsync- 把linux121机器上的/opt/lagou/software目录同步到linux122服务器的root用户下的/opt/目录
[root@linux121 opt]$ rsync -rvl /opt/lagou/software/ root@linux122:/opt/lagou/software集群分发脚本编写
需求:循环复制文件到集群所有节点的相同目录下
rsync命令原始拷贝:
rsync -rvl /opt/module root@linux123:/opt/期望脚本
脚本+要同步的文件名称
说明:在/usr/local/bin这个目录下存放的脚本,root用户可以在系统任何地方直接执行。
脚本实现
在/usr/local/bin目录下创建文件rsync-script,文件内容如下:
[root@linux121 bin]$ touch rsync-script [root@linux121 bin]$ vim rsync-script在文件中编写shell代码
#!/bin/bash #1 获取命令输入参数的个数,如果个数为0,直接退出命令 paramnum=$# if((paramnum==0)); then echo no params; exit; fi #2 根据传入参数获取文件名称 p1=$1 file_name=`basename $p1` echo fname=$file_name #3 获取输入参数的绝对路径 pdir=`cd -P $(dirname $p1); pwd` echo pdir=$pdir #4 获取用户名称 user=`whoami` #5 循环执行rsync for((host=121; host<124; host++)); do echo -------------linux$host ------------- rsync -rvl $pdir/$file_name $user@linux$host:$pdir done修改脚本 rsync-script 具有执行权限
[root@linux121 bin]$ chmod 777 rsync-script- 调用脚本形式:rsync-script 文件名称
[root@linux121 bin]$ rsync-script /home/root/bin执行该路径会报错,先不理会
- 调用脚本分发Hadoop安装目录到其它节点
[root@linux121 bin]$ rsync-script /opt/lagou/servers/hadoop-2.9.2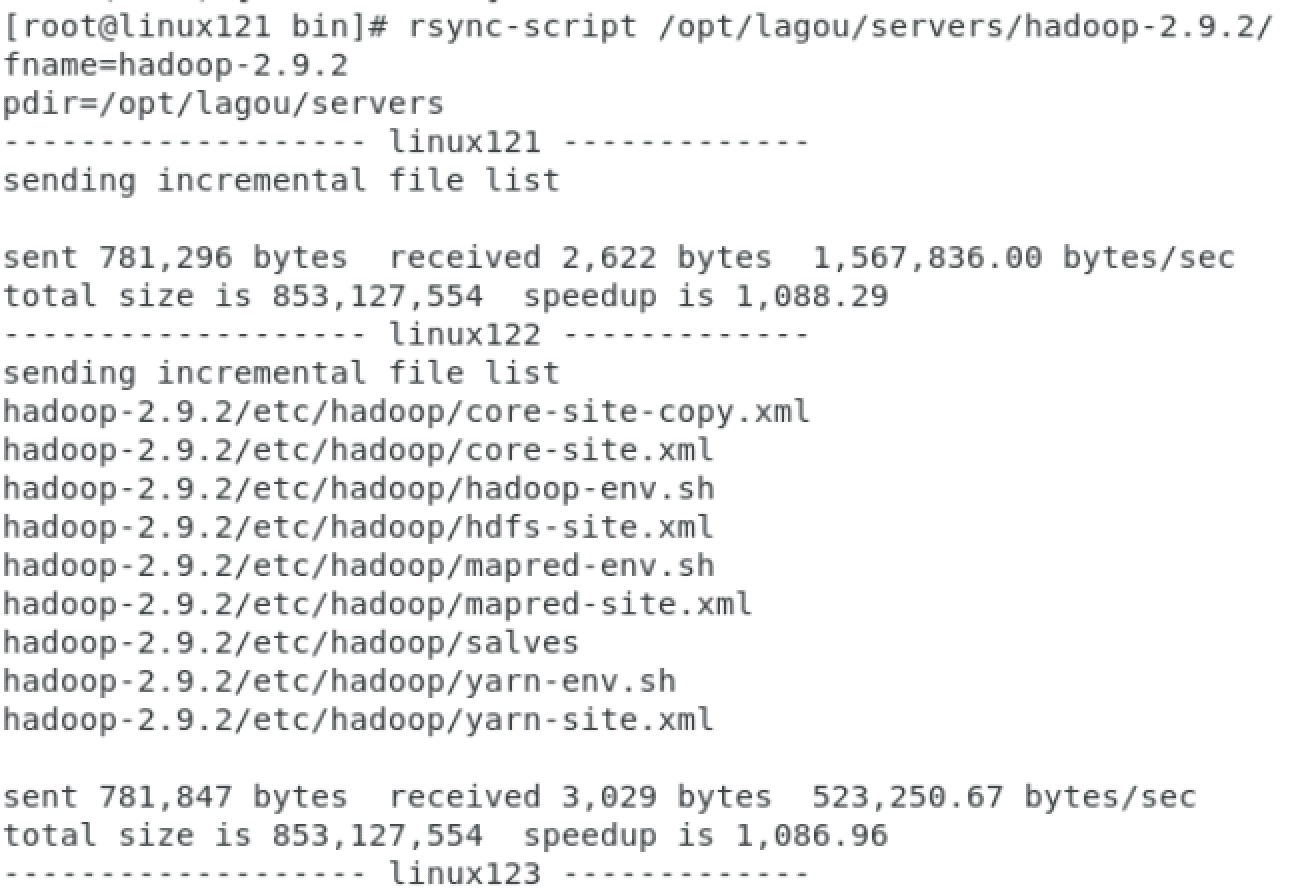
启动集群
注意:如果集群是第一次启动,需要在Namenode所在节点格式化NameNode,非第一次不用执行格 式化Namenode操作!!
单节点启动
[root@linux121 hadoop-2.9.2]$ hadoop namenode -format格式化命令执行效果:
格式化后创建的文件:/opt/lagou/servers/hadoop-2.9.2/data/tmp/dfs/name/current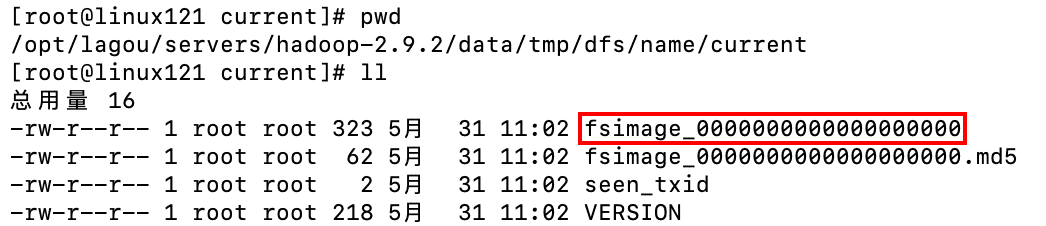
在linux121上启动NameNode
[root@linux121 hadoop-2.9.2]$ hadoop-daemon.sh start namenode [root@linux121 hadoop-2.9.2]$ jpsjps是jdk提供的一个查看当前java进程的小工具,JavaVirtual Machine Process Status Tool的缩写
在linux121、linux122以及linux123上分别启动DataNode
[root@linux121 hadoop-2.9.2]# hadoop-daemon.sh start namenode starting namenode, logging to /opt/lagou/servers/hadoop-2.9.2/logs/hadoop-root-namenode-linux121.out [root@linux121 hadoop-2.9.2]# jps 75537 Jps 75452 NameNodeweb端查看Hdfs界面
- http://linux121:50070/dfshealth.html#tab-overview【主机已配置域名映射点击这个链接】
- http://192.168.80.121:50070/dfshealth.html#tab-overview【主机未配置域名映射点击这个链接】
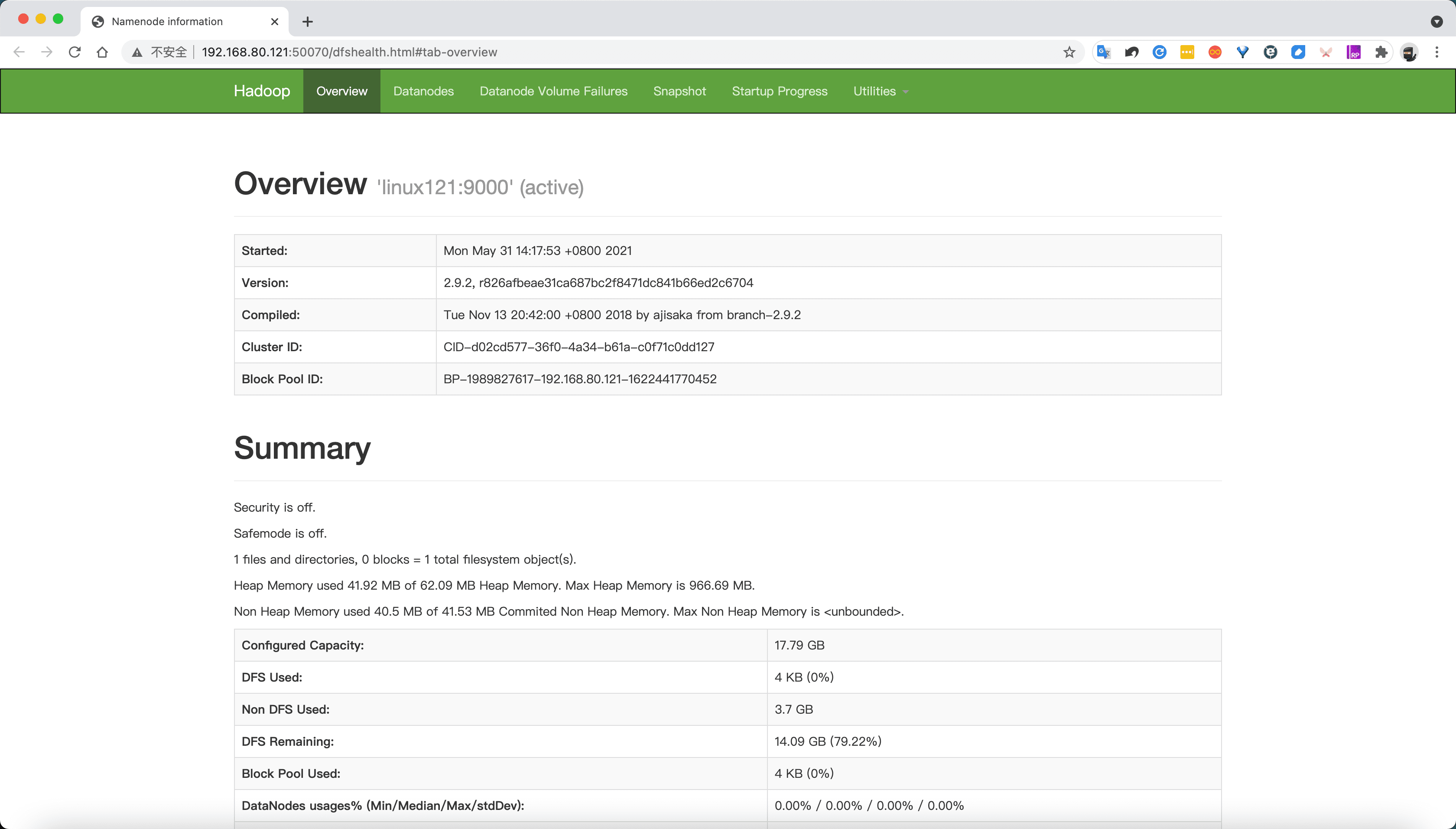
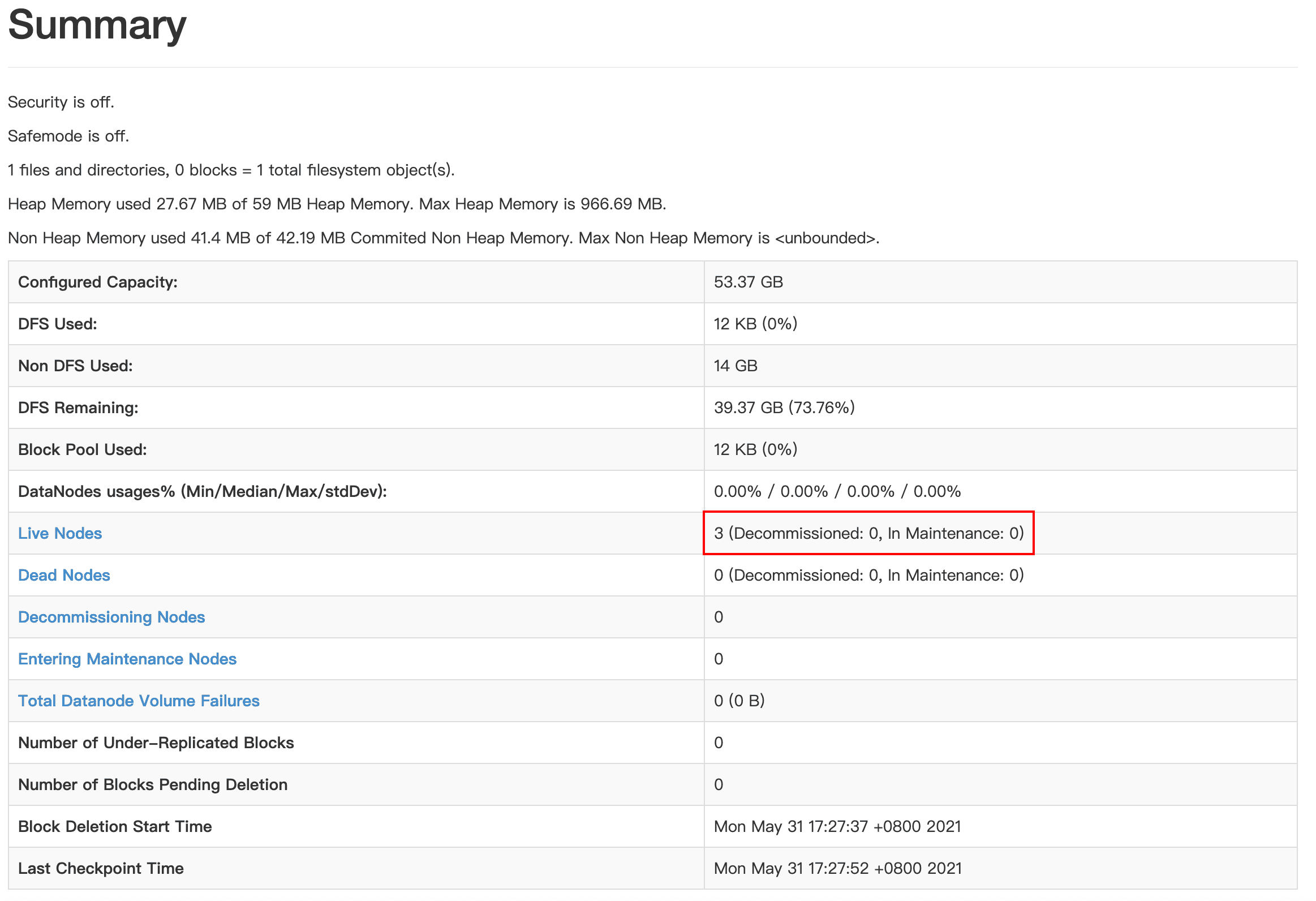
点击Live Nodes查看详情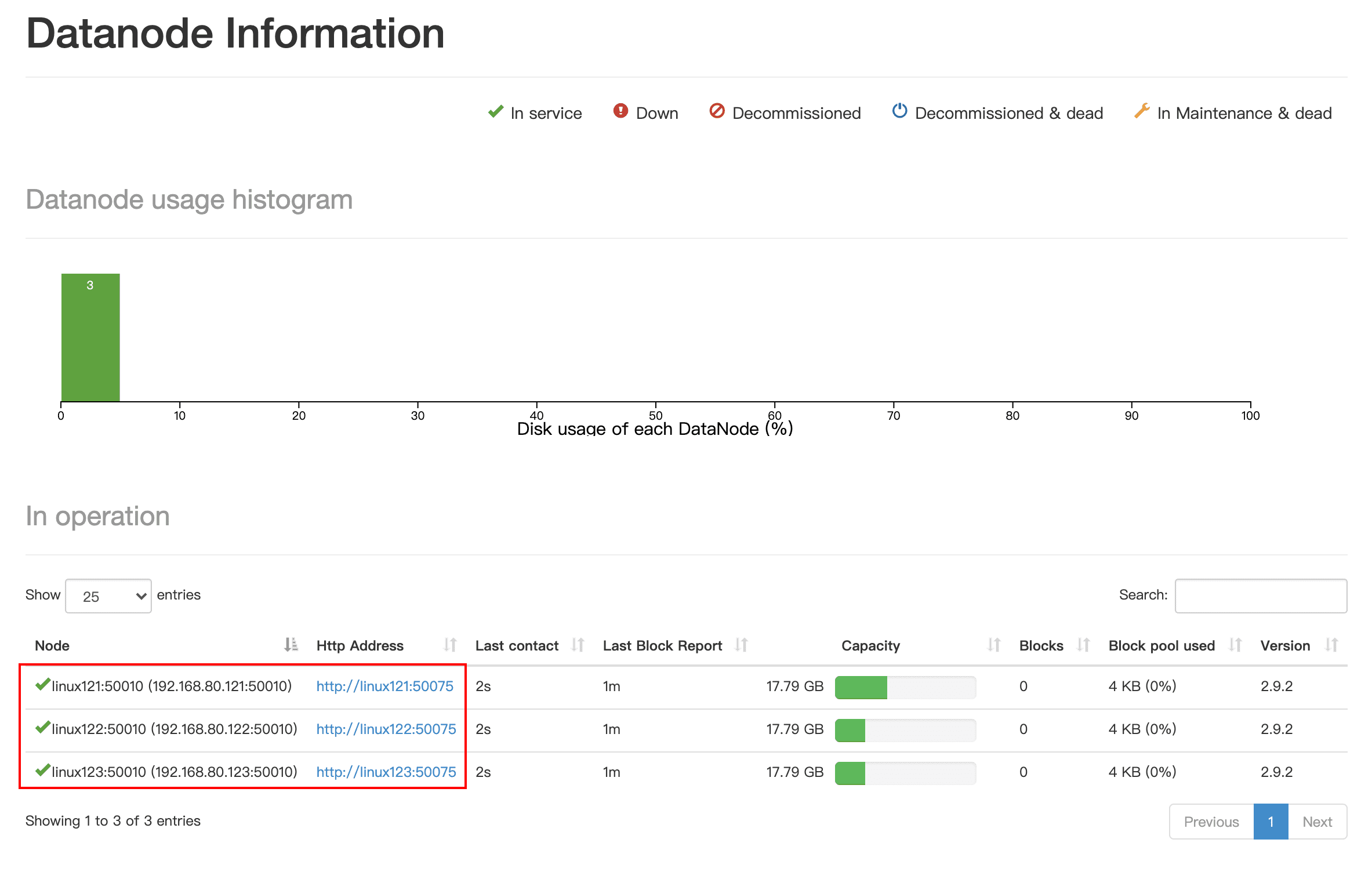
若配置后,没有按照预期的显示
关闭集群,把三台机子上的Hadoop安装目录下的data、logs文件夹均删除,然后格式化namenode,最后重启集群
集群群起
如果已经单节点方式启动了Hadoop,可以先停止之前的启动的Namenode与Datanode进程,如果之前Namenode没有执行格式化,这里需要执行格式化!!!!
hadoop namenode -format启动HDFS
[root@linux121 hadoop-2.9.2]$ sbin/start-dfs.sh [root@linux121 hadoop-2.9.2]$ jps 4166 NameNode 4482 Jps 4263 DataNode [root@linux122 hadoop-2.9.2]$ jps 3218 DataNode 3288 Jps [root@linux123 hadoop-2.9.2]$ jps 3221 DataNode 3283 SecondaryNameNode 3364 Jps启动YARN
NameNode和ResourceManger不是在同一台机器,不能在NameNode上启动 YARN,应该 在ResouceManager所在的机器上启动YARN。
在linux123上启动yarn
[root@linux123 hadoop-2.9.2]$ sbin/start-yarn.shHadoop集群启动停止命令汇总
各个服务组件逐一启动/停止
# 分别启动/停止HDFS组件
hadoop-daemon.sh start|stop namenode|datanode|secondarynamenode
# 启动/停止YARN
yarn-daemon.sh start|stop resourcemanager|nodemanager各个模块分开启动/停止(配置ssh是前提)常用
# 整体启动/停止HDFS
start-dfs.sh
stop-dfs.sh
# 整体启动/停止YARN
start-yarn.sh
stop-yarn.sh


